
Chaos engineering is a powerful tool for ensuring system reliability and performance, and its application in designing Chaos experiments for Ingress Controllers can help organizations identify weaknesses in their applications and infrastructure.
Overview
Chaos Engineering plays a crucial role in assessing and enhancing the resilience and reliability of software systems. By simulating disruptive events, organizations can identify vulnerabilities and improve the system's design and architecture. In this article, we will discuss the importance of Chaos Engineering and its specific application in designing Chaos experiments for Ingress Controllers.
Why We Need Chaos Engineering?
Chaos Engineering is the process of evaluating software systems by simulating destructive events, such as server network outages or API throttling. By introducing chaos or faults within the system, we can test the system's resilience and reliability in unstable and unexpected conditions.
Chaos Engineering helps teams identify hidden risks, monitor vulnerabilities, and identify performance bottlenecks in distributed systems by simulating real-world scenarios in a secure control environment. This approach effectively prevents system downtime or production interruptions.
Netflix's approach to handling systems inspired us to adopt a more scientific approach, which drove the birth and development of Chaos Engineering.
1. Introduction of Disruptive Events
Chaos Engineering involves introducing disruptive events, such as network partitions, service degradation, and resource constraints, to simulate real-world scenarios and test the system's ability to handle unexpected conditions. The purpose is to identify vulnerabilities or weaknesses and improve the system's design and architecture to make it more robust and resilient.
2. Testing System Resilience
In today's constantly evolving and fast-paced technology landscape, testing system resilience is crucial to ensure that systems are robust, scalable, and capable of handling unexpected challenges and conditions. Chaos Engineering is an effective way to achieve this by introducing disruptive events to observe the system's response and measure its ability to handle unexpected conditions.
Organizations can monitor system logs, performance metrics, and user experience to measure the impact of disruptive events on system resilience. Tracking these metrics provides a better understanding of the system's behavior, allowing organizations to identify areas for improvement.
3. Discovering Hidden Problems
Distributed systems are prone to hidden issues, such as data loss, performance bottlenecks, and communication errors, which can be challenging to detect, as they may only become visible when the system is under pressure. Chaos Engineering can help uncover these hidden issues by introducing disruptive events. This information can then be used to improve the system's design and architecture, making it more resilient and reliable.
Proactively identifying and resolving these problems enhances the reliability and performance of systems, preventing downtime, reducing the risk of data loss, and ensuring the system runs smoothly.
4. What It's Worth and Why We Need It?
Distributed systems are complex and inherently chaotic, which can lead to failure. The use of cloud and microservices architecture provides many advantages but also comes with complexity and chaos. Engineers are responsible for making the system as reliable as possible.
Without testing, there is no confidence to use the project in the production environment. In addition to conventional unit tests and end-to-end tests, introducing chaos tests makes the system more robust.
When an error occurs, repairing it takes time and can cause immeasurable losses, with long-term effects in the future. During the repair process, various factors need consideration, including the system's complexity, the type of error, and possible new problems, to ensure effective final repair.
Furthermore, when an open-source project brings serious faults to users in the production environment, many users may switch to other products.
How to Design Chaos Experiments for an Ingress Controller?
1. What Is Ingress?
Ingress is a Kubernetes resource object that contains rules for how external clients can access services within the cluster. These rules dictate which clients can access which services, how client requests are routed to the appropriate services, and how client requests are handled.
2. What Is an Ingress Controller?
An Ingress resource requires an Ingress Controller to process it. The controller translates the Ingress rules into configurations on a proxy, allowing external clients to access services within the cluster. In a production environment, Ingress Controllers need to have complex capabilities, such as limiting access sources and request methods, authentication, and authorization. Most Ingress Controllers extend the semantics of Ingress through annotations in the Ingress resource.
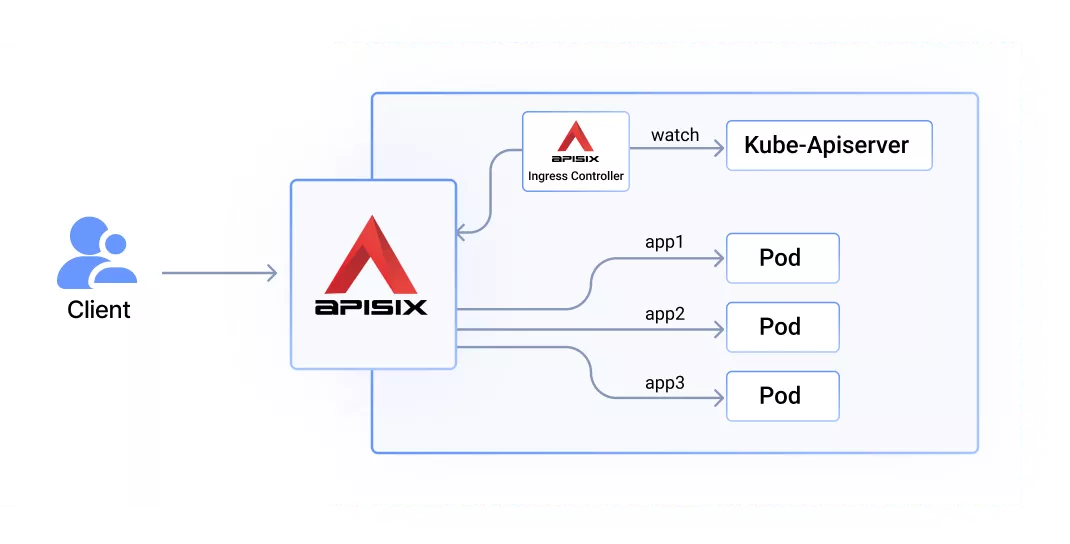
3. What Is Apache APISIX Ingress Controller?
Apache APISIX Ingress Controller is a specialized type of load balancer that helps administrators manage and control Ingress traffic. It uses APISIX as a data plane to provide users with dynamic routing, load balancing, elastic scaling, security policies, and other features to improve network control and ensure higher availability and security for their business. APISIX Ingress Controller supports three configuration modes: Kubernetes Ingress, custom resources, and Gateway API.

4. What Is Litmus Chaos?
Litmus Chaos is an open-source Chaos Engineering framework that provides an infrastructure experimental framework to validate the stability of controllers and microservices architectures. It can simulate various environments, such as container-level and application-level environments, natural disasters, faults, and upgrades, to understand how the system responds to these changes. The framework can also explore the behavior changes between controllers and applications, and how controllers respond to challenges in specific states. Litmus Chaos offers convenient observability integration capabilities and is highly extensible.
5. How to Design Chaos Experiments?
Here is a general procedure for designing chaos experiments in any scenario:
- Define the system under test: Identify the specific components of the system you want to experiment on and develop clear and measurable objectives for the experiment. This includes creating a comprehensive list of the components, such as hardware and software, that will be tested, as well as defining the scope of the experiment and the expected outcomes.
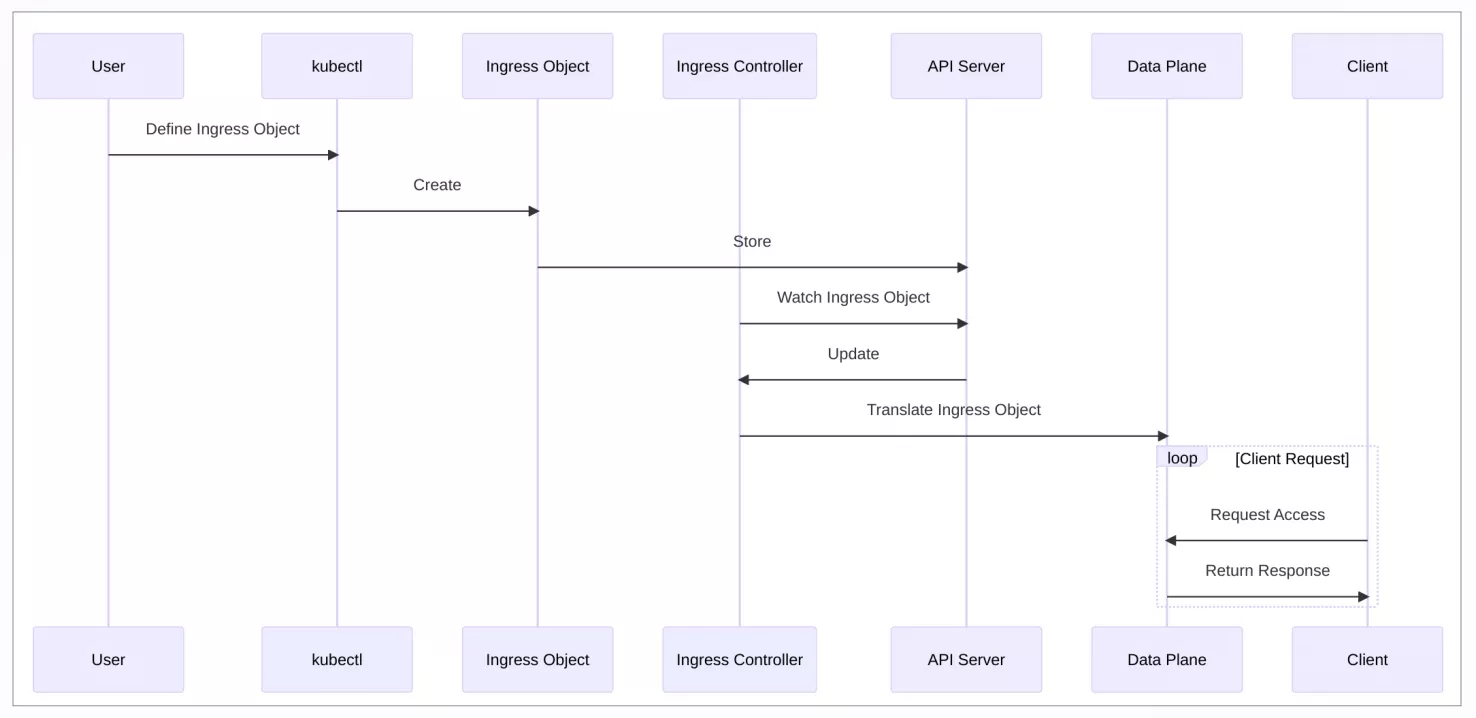

kube-apiserver: if an exception occurs, the Ingress resource write failed. Ingress-controller: Network interruption, Crash, Podfaults, I/O data-plane: Network interruption, Crash, Podfaults, I/O
- Choose the right experiment: Select an experiment that is aligned with the objectives you have set and closely mimics a real-world scenario. This will help ensure that the experiment produces meaningful results and accurately reflects the behavior of the system.
- Establish a hypothesis: Establish a hypothesis about how the system will behave during the experiment and what outcomes you anticipate. This should be based on experience or research, and it should be reasonable and testable.
- Run the experiment: Run the experiment in a controlled environment, such as a staging environment, to limit the potential for harm to the production system. Collect all relevant data during the experiment and store it securely. There may be differing opinions on whether the experiment should take place directly in the production environment. However, for most scenarios, we need to ensure the Service Level Objective (SLO) of the system is met.
- Evaluate the results: Evaluate the results of the experiment and compare them to your hypothesis. Analyze the data collected and document any observations or findings. This includes identifying any unexpected results or discrepancies and determining how they might affect the system. Additionally, consider how the results of the experiment can be used to improve the system.
Main Usage Scenarios of Ingress Controller
The most important capability of an Ingress Controller is to proxy traffic, and all other functions are based on this core function. Therefore, when conducting Chaos Engineering, normal proxy traffic is the key metric.
To define the system under test for APISIX Ingress Controller, users need to create route configurations, such as Ingress, Gateway API, or CRD, and apply them to the Kubernetes cluster via Kubectl. This process goes through kube-apiserver for authentication, authorization, admission and other related procedures, and is then stored in etcd.
The APISIX Ingress Controller continuously watches for changes in Kubernetes resources. These configurations are then converted to configurations on the data plane. When a client requests the data plane, it accesses the upstream service according to the routing rules.
If kube-apiserver has an exception, it will prevent the configuration from being created, or the Ingress Controller from getting the correct configuration. Similarly, if there is an exception in the data plane, such as a network interruption or Pod killed, it will also not be able to do normal traffic proxy.
The scope of our experiment is mainly the impact on system availability if the Ingress Controller has an exception.
1. Detailed Operation Steps
- Choose the right experiment: We can cover many scenarios of incorrect configuration through end-to-end tests. Mainly through Chaos Engineering, we can verify whether the data plane can still proxy traffic normally when the Ingress Controller encounters an exception, such as DNS errors, network interruptions, or Pod killed.
- Establish a hypothesis: For each scenario, we can create a hypothesis such as "When the Ingress-controller Pod gets
X?, the client's request can still get a normal response." - Run the experiment: The experiment and variables have been determined, so all that's left is to experiment.
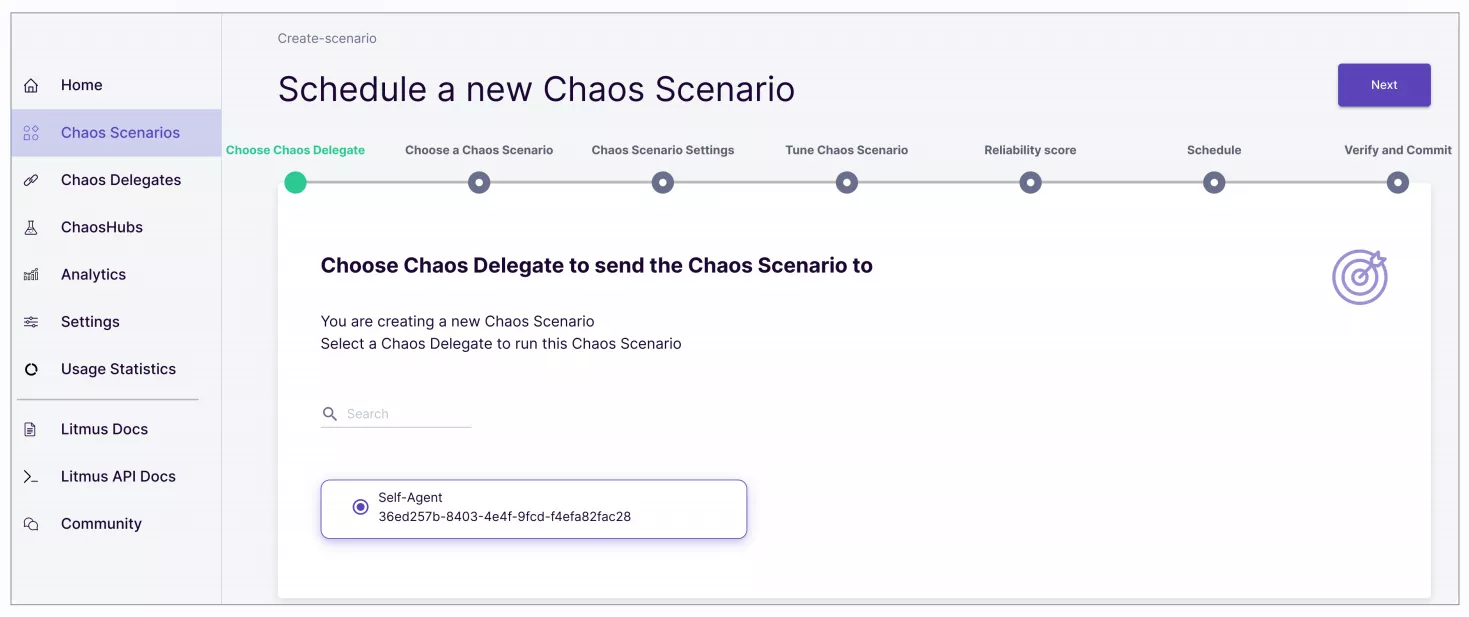
Litmus Chaos provides various ways to conduct experiments. We can do this through the Litmus Portal. To do this, we need to create a Chaos scenario, select the application to be experimented on, and these steps are relatively straightforward. However, we must pay attention to the fact that Litmus Chaos includes a Probes resource.
Probes are pluggable checks that can be defined within the ChaosEngine for any Chaos Experiment. The experiment pods execute these checks based on the mode they are defined in and factor their success as necessary conditions in determining the verdict of the experiment, in addition to the standard in-built checks. At the same time, we can also schedule experiments, which is a very valuable function.
Additionally, Litmus Chaos also supports running experiments by submitting YAML manifests.
- Evaluate the results: Litmus Chaos has built-in statistical reports, and it can be integrated with Prometheus and Grafana to provide a unified dashboard for integration.
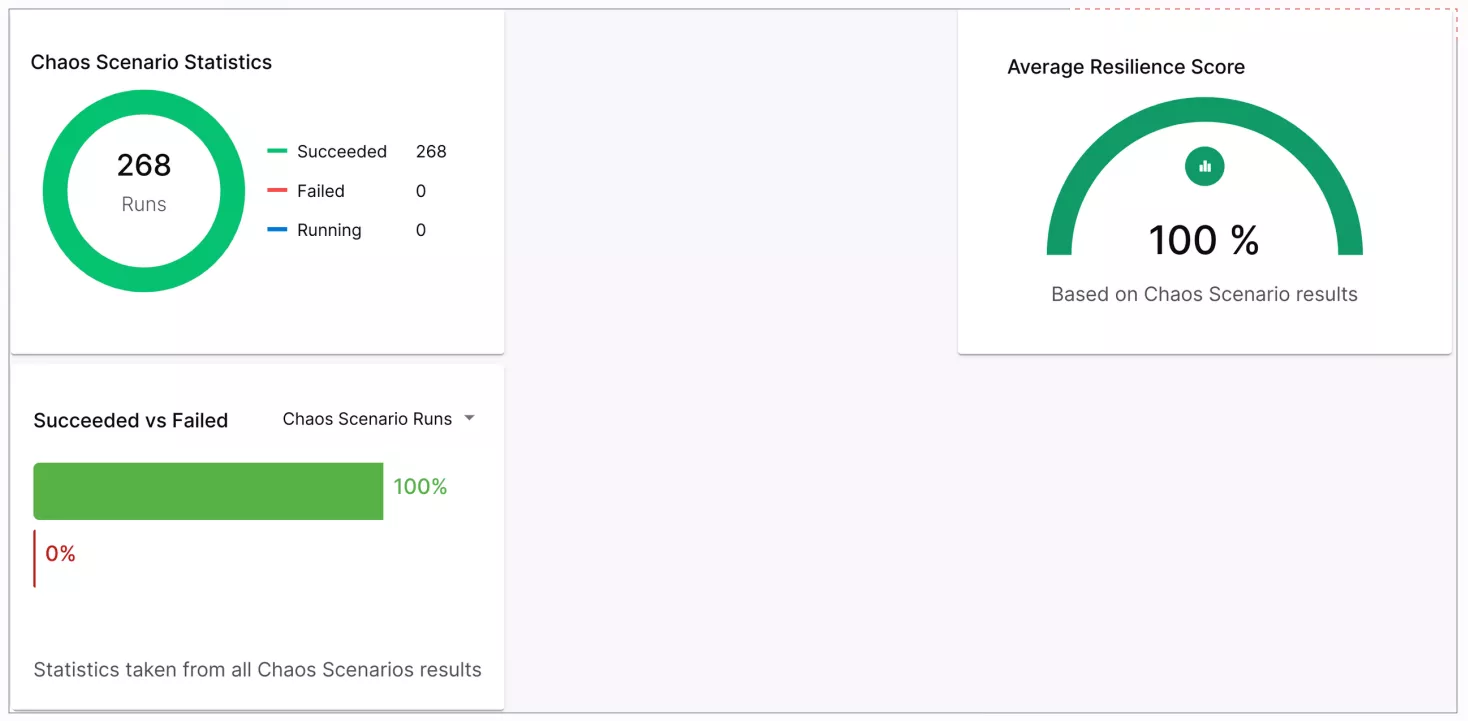
2. Benefits and Future
Through rigorous end-to-end testing and the power of Chaos Engineering, we're confident in the stability and reliability of the delivered APISIX Ingress Controller. Chaos Engineering has also helped us to identify and fix bugs. We're constantly working to improve and evolve this amazing project, and we invite you to join our community.